dimanche 13 janvier 2013
C'est quoi XML ?
بتاريخ 12:43 بواسطة Unknown
Un fichier XML est un fichier texte possédant une structure particulière.
XML est une notation, c'est à dire une manière d'écrire les informations.
On utilise des balises pour délimiter les informations, par exemple:
XML est une notation, c'est à dire une manière d'écrire les informations.
On utilise des balises pour délimiter les informations, par exemple:
<TITRE>20000 Lieues sous les mers</TITRE>
<AUTEUR>Jules Vernes</AUTEUR>
Comme vous le voyez les balises <TITRE> ou <AUTEUR> permettent de délimiter les informations correspondant au titre et à l'auteur.
<TITRE> annonce le début des informations concernant le titre.
</TITRE> annonce la fin des informations concernant le titre (notez le slash "/").
Ceux qui ont déjà fait du HTML sont en terrain connu: à quelques différences près, XML est très similaire au HTML, mais en XML vous pouvez définir vos propres balises.
Hiérarchie
XML permet d'imbriquer les balises. C'est à dire qu'une balise peut contenir des informations, mais aussi d'autres balises.
Prenons un petit exemple: Je vais créer une bibliothèque.
<BIBLIOTHEQUE>
<ROMAN>
<TITRE>Imajica</TITRE>
<AUTEUR>Clive Barker</AUTEUR>
<PRIX>6</PRIX>
</ROMAN>
<ROMAN>
<TITRE>Dune</TITRE>
<AUTEUR>Frank Herbert</AUTEUR>
<PRIX>7</PRIX>
</ROMAN>
<MAGAZINE>
<TITRE>Science et Vie</TITRE>
<DATEPARUTION>2005-02-01</DATEPARUTION>
</MAGAZINE>
<ROMAN>
<TITRE>Christine</TITRE>
<AUTEUR>Stephen King</AUTEUR>
<PRIX>5</PRIX>
</ROMAN>
</BIBLIOTHEQUE>
<ROMAN>
<TITRE>Imajica</TITRE>
<AUTEUR>Clive Barker</AUTEUR>
<PRIX>6</PRIX>
</ROMAN>
<ROMAN>
<TITRE>Dune</TITRE>
<AUTEUR>Frank Herbert</AUTEUR>
<PRIX>7</PRIX>
</ROMAN>
<MAGAZINE>
<TITRE>Science et Vie</TITRE>
<DATEPARUTION>2005-02-01</DATEPARUTION>
</MAGAZINE>
<ROMAN>
<TITRE>Christine</TITRE>
<AUTEUR>Stephen King</AUTEUR>
<PRIX>5</PRIX>
</ROMAN>
</BIBLIOTHEQUE>
Notre bibiothèque contient diverses choses: trois romans et un magazine.
Chaque roman possède un titre, un auteur et un prix.
Chaque magazine possède un titre et une date de parution.
On peut ainsi imbriquer autant que l'on veut les informations.
XML est très bien adapté à la représentation d'informations hiérarchiques.
Quel intérêt à utiliser XML ?
Vous aurez remaqué que notre exemple ci-dessus est humainement compréhensible.
Grâce aux balises, l'ordinateur est également capable d'en traiter le contenu (et de bien séparer les informations).
C'est un des avantages du XML: c'est l'un des rares formats qui peut être à la fois lu par un humain et par un ordinateur.
De plus, en se mettant d'accord sur les balises à utiliser, on peut utiliser XML pour échanger des informations entre différentes personnes et logiciels.
XML, grâce à l'utilisation de l'encodage d'UTF-8, supporte très bien tous les alphabets du monde.
Mais en plus de cela, XML est entouré de tout un tas d'outils pour manipuler les documents XML: XSD, XSLT, XQuery...
XSD: Vérifier
Ci-dessus, j'ai inventé un format XML spécial pour ma bibliothèque.
Il faudrait que je donne une définition précise de sa structure (quelle balise doit contenir quelle autre, quel type d'information peut contenir une balise (nombre, texte...), quelles balises sont obligatoires ou non, etc.).
C'est ce que permet le format XSD.
Je vais donc écrire un fichier XSD, qui va contenir la définition de la structure de ma bibliothèque.
N'importe qui pourra ensuite utiliser ce fichier XSD pour vérifier qu'un fichier XML quelquonque est au même format que ma bibliothèque (même s'il contient d'autres romans ou magazines). Grâce au fichier XSD, l'ordinateur sera capable de dire si un fichier XML correspond ou non à la structure d'une bibliothèque.
Si je reçois un fichier XML et que l'ordinateur (grâce au XSD) me dit qu'il est au bon format, je sais que je serai capable d'en comprendre le contenu (puisque ce ne sera pas une structure inconnue).
(Note: XSD est lui-même un fichier XML !)
Voici un exemple (ne vous focalisez pas trop sur le contenu, c'est à titre d'exemple, purement facultatif):
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified" attributeFormDefault="unqualified">
<xs:element name="BIBLIOTHEQUE">
<xs:complexType>
<xs:choice maxOccurs="unbounded">
<xs:element name="MAGAZINE">
<xs:complexType>
<xs:sequence>
<xs:element name="TITRE" type="xs:string"/>
<xs:element name="DATEPARUTION" type="xs:date"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="ROMAN">
<xs:complexType>
<xs:sequence>
<xs:element name="TITRE" type="xs:string"/>
<xs:element name="AUTEUR" type="xs:string"/>
<xs:element name="PRIX" type="xs:integer"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:choice>
</xs:complexType>
</xs:element>
</xs:schema>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified" attributeFormDefault="unqualified">
<xs:element name="BIBLIOTHEQUE">
<xs:complexType>
<xs:choice maxOccurs="unbounded">
<xs:element name="MAGAZINE">
<xs:complexType>
<xs:sequence>
<xs:element name="TITRE" type="xs:string"/>
<xs:element name="DATEPARUTION" type="xs:date"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="ROMAN">
<xs:complexType>
<xs:sequence>
<xs:element name="TITRE" type="xs:string"/>
<xs:element name="AUTEUR" type="xs:string"/>
<xs:element name="PRIX" type="xs:integer"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:choice>
</xs:complexType>
</xs:element>
</xs:schema>
- Je définie que BIBLIOTHEQUE peut contenir au choix (
xs:choice) un nombre quelquonque (maxOccurs="unbounded") d'élements ROMAN et MAGAZINE. - Chaque MAGAZINE comprend obligatoirement une séquence (
xs:sequence) de deux éléments: un TITRE et une DATEPARUTION. - La DATEPARUTION contient obligatoirement une date (
type="xs:date", format année-mois-jour) - etc.
XSLT: Transformer
Imaginons que je veuille publier ma bibliothèque sur le web (au format HTML), et dans un fichier Excel (CSV). Il va falloir que je créé à la main un fichier HTML et le fichier CSV.Et si le contenu de ma bibliothèque change, il faudra que je mette à jour à la main le fichier HTML et le fichier CSV.
C'est fastidieux.
XSLT va permettra d'automatiser cela.
Je vais donc écrire un fichier XSLT qui va décrire les transformations à appliquer à ma bibliothèque XML pour en faire un fichier HTML.
De même, je vais écrire un second fichier XSLT qui va décrire les transformations à appliquer à mon XML pour en faire un fichier CSV.

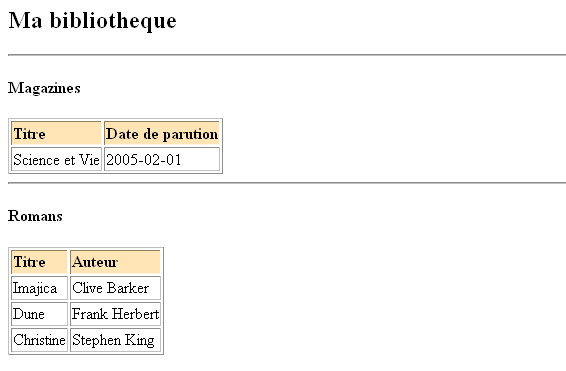
Je commence par écrire un XSLT qui va transformer en HTML.
<?xml version="1.0" encoding="ISO-8859-1"?>Cela va créer le fichier HTML suivant:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<body>
<h2>Ma bibliotheque</h2>
<hr/>
<h4>Magazines</h4>
<table border="1">
<tr bgcolor="#ffe4b5"><th align="left">Titre</th><th align="left">Date de parution</th></tr>
<xsl:for-each select="/BIBLIOTHEQUE/MAGAZINE">
<tr><td><xsl:value-of select="TITRE"/></td><td><xsl:value-of select="DATEPARUTION"/></td></tr>
</xsl:for-each>
</table>
<hr/>
<h4>Romans</h4>
<table border="1">
<tr bgcolor="#ffe4b5"><th align="left">Titre</th><th align="left">Auteur</th></tr>
<xsl:for-each select="/BIBLIOTHEQUE/ROMAN">
<tr><td><xsl:value-of select="TITRE"/></td><td><xsl:value-of select="AUTEUR"/></td></tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
(J'ai volontairement omis le PRIX de mon fichier XLST, car je ne veux pas le publier dans ma page HTML.)
Et je procède de la même façon pour créer un fichier XLST pour le format CSV (Excel):
<?xml version="1.0" encoding="ISO-8859-1"?>Cela va créer un fichier .CSV que l'on peut ensuite directement ouvrir dans Excel ou OpenOffice.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">Type,Titre, Auteur, Date de parution
<xsl:for-each select="/BIBLIOTHEQUE/MAGAZINE">Magazine,<xsl:value-of select="TITRE"/>,,<xsl:value-of select="DATEPARUTION"/>,
</xsl:for-each>
<xsl:for-each select="/BIBLIOTHEQUE/ROMAN">Roman,<xsl:value-of select="TITRE"/>,<xsl:value-of select="AUTEUR"/>,
</xsl:for-each></xsl:template>
</xsl:stylesheet>

Ce qui est formidable, c'est que si je modifie ma bibliothèque, il suffit de ré-appliquer les XLST pour produire automatiquement les fichiers HTML et CSV !
Je n'aurai rien à faire à la main.
Et si je donne ces XLST à tout le monde, chacun pourra publier sa bibliothèque de la même façon.
XML permet donc - en théorie - de stocker des informations indépendamment de leur représentation.
On peut ensuite, grâce à XSLT, représenter ces informations d'une manière ou d'une autre, selon les besoins.
XQuery et XPath
XQuery et XPath permettent d'extraire les informations qui vous intéresse d'un document XML (Un peu à la manière des requêtes SQL, pour ceux qui connaissent.)
Par exemple, pour extraire uniquement les romans de notre bibliothèque, on ferait:
/BIBLIOTHEQUE/ROMANce qui donne:
<ROMAN>
<TITRE>Imajica</TITRE>
<AUTEUR>Clive Barker</AUTEUR>
<PRIX>6</PRIX>
</ROMAN>
<ROMAN>
<TITRE>Dune</TITRE>
<AUTEUR>Frank Herbert</AUTEUR>
<PRIX>7</PRIX>
</ROMAN>
<ROMAN>
<TITRE>Christine</TITRE>
<AUTEUR>Stephen King</AUTEUR>
<PRIX>5</PRIX>
</ROMAN>
Ou encore, si on veut tous les auteurs dont les romans coûtent plus de 5 euros:
/BIBLIOTHEQUE/ROMAN[PRIX>5]/AUTEURce qui donne:
<AUTEUR>Clive Barker</AUTEUR>C'est exactement ce que nous voulions: uniquement les auteurs des romans dont le prix est supérieur à 5 euros.
<AUTEUR>Frank Herbert</AUTEUR>
XQuery et XPath permettent donc d'extraire juste l'information qui vous intéresse de tout fichier XML.
Et les autres...
En combinant les différentes techniques tournant autant d'XML, on peut faire beaucoup de choses.Et ces techniques sont nombreuses !
Voir (en anglais): http://www.wdvl.com/Authoring/Languages/XML/XMLFamily/BigPicture/bigpix20a.html

Mais XML n'a pas que des avantages...
Tout d'abord, XML est très verbeux. C'est à dire qu'il utilise beaucoup de caractères.
Par exemple, si on veut noter le nombre d'exemplaires, on ferait sûrement: <NOMBREEXEMPLAIRES>5</NOMBREEXEMPLAIRES>
L'information elle-même n'occupe qu'un octet ("5"), mais on l'a encadré de 39 octets.
C'est un énorme gaspillage de place.
Ensuite, ce format étant en texte, l'ordinateur est obligé de tout convertir en binaire (pour s'en faire une "représentation" en mémoire), faire ses traitements, puis tout reconvertir en texte dans l'autre sens. Cela prend beaucoup de temps (surtout quand on a beaucoup d'XML à traiter).
Ensuite, l'XML est très bien adapté à la représentation d'informations hiérarchiques, mais que des informations hiérarchiques.
Il est très mal adapté à la représentation d'autres types de données, comme les données relationnelles.
Par exemple: Un catalogue contient plusieurs produit, ces produits ont été commandés dans telle et telle commande, cette commande vient de tel client, etc. XML est mal adapté au stockage de telles informations, au contraire des bases de données relationnelles.
Dans la vraie vie, toutes les informations n'entrent pas dans de petites catégories bien hiérarchisées.
L'XML est également incapable de stocker des informations binaires, comme des images, vidéos ou musiques.
Il existe bien une astuce pour représenter sous forme de texte des données binaires (l'encodage en base64), mais on perd énormément de place. (Un fichier de 100 000 octets prendra 136 848 octets en base64 !)
Et enfin, dans la pratique, les fichiers XML qu'on rencontre sont fortement imbriqués, ce qui rend la lecture par un humain quasi-impossible.
De plus, les technologie qui tournent autour d'XML (XSD, XSLT, XPath...) sont nombreuses et complexes: il est difficile de bien les maîtriser.
Certaines ne sont pas adoptées par tout le monde, ou sont poussées par des entreprises pour leur propre intérêt.
Donc l'XML n'est pas la panacée. Il ne faut pas vouloir faire de l'XML à tout prix parceque c'est à la mode.
Il peut rendre de grands services, mais il ne faut l'utiliser que quand il apporte quelquechose.
XML n'est que l'une des nombreuses manières de stocker et transmettre de l'information.
Où retrouve-t-on de l'XML ?
On en retrouve un peu partout.
- On en retrouve dans les pages web: l'XHTML (validé par le W3C) est le successeur d'HTML. XHTML a la particularité d'être du vrai XML (ce qui n'est pas le cas d'HTML 4).
- Les documents OpenOffice (.sxw par exemple) sont également des fichiers XML, zippés dans un même fichier.
- Certains logiciels de chat comme Jabber utilisent XML pour échanger les messages.
- Le format graphique SVG permet de définir des formes géométriques. La plupart des navigateurs récents sont capables de les afficher dans les pages web. C'est également le format utilisé par des logiciels de dessin comme InkScape et Sodipodi.
- MathML permet de décrire et échanger des formules mathématiques.
- SMIL est un format conçu pour les présentations multimédia. C'est également du XML.
- RSS permet aux sites web de publier leurs informations. Les logiciels comprenant RSS sont capables de récupérer les infos des sites qui vous intéressent, les aggréger et vous les présenter. RSS utilise un schéma XML particulier.
- Java (applets et programmes) et Microsoft .Net (inclu dans Windows XP) utilisent des fichiers XML pour décrire les programmes et leurs paramètres de sécurité.
- XML-RPC et SOAP permettent à des programmes d'appeller des fonctions d'autres programmes à travers internet: c'est ce qu'on appelle les webservices. XML-RPC et SOAP utilisent exclusivement XML.
- Des systèmes comme Rosetta.Net ou UBL (Universal Business Language) sont conçus pour permettre aux entreprise d'échanger des commandes, des factures, des devis...
- Le logiciel FreeMind utilise le format XML pour sauvegarder (fichiers .mm).
- Beaucoup de logiciels utilisent le format XML pour stocker leur configuration.
Chacun de ces formats utilise un schéma XSD particulier.
Vous pouvez télécharger le fichier ZIP contenant tous les fichiers d'exemple de cette page: fichiers_exemple.zip
Inscription à :
Publier les commentaires (Atom)

ردود على "C'est quoi XML ? "
أترك تعليقا